














勞動經濟學/監察AI演變 撫平勞動市場波動\張丹丹
2026.03.28 04:20:49
 字號:
字號:
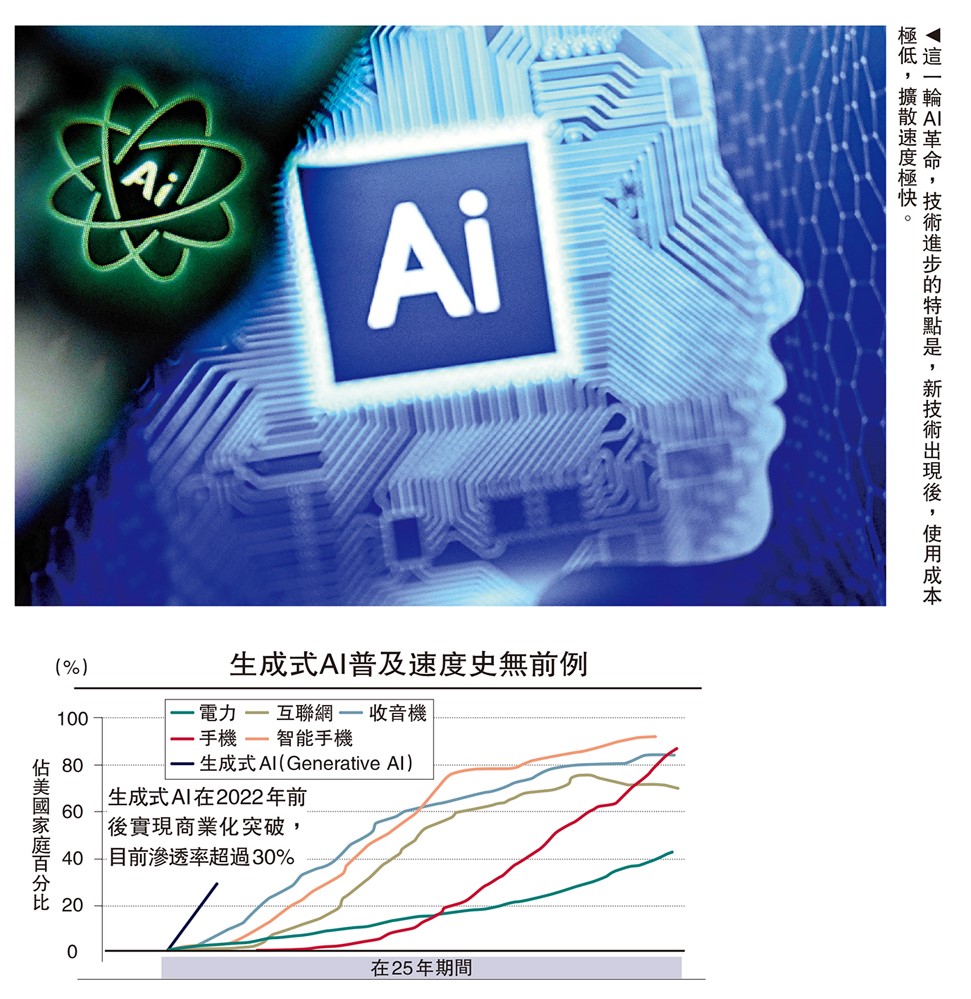
當前AI技術迭代迅猛,已從「輔助人」轉向「替代人完成完整任務鏈」。本輪技術進步的使用成本極低、擴散速度極快,對勞動力市場的影響速度遠超以往,需要引起高度重視。
從技術背景來看,如果說以往的技術進步更多是對「腦力」的輔助或對某些任務的替代,那麼這一次開始出現對「手」的替代,也就是所謂的通用人工智能(AGI)趨勢。Open Claw出現後,任務可以自主執行。過去AI替代的是整個任務鏈中的某一個環節,而現在它可以完整地執行一整套任務鏈條。
這種替代看起來很難避免─至少對任務的替代、對崗位的替代,甚至對一個機構或一個行業的替代,未來是難以避免的。
須關心的問題在於:替代的速度與崗位創造的速度之間,究竟是怎樣的關係?正如一些專家提到的,如果崗位創造的速度足夠快,我們其實不必過度擔憂。
這一輪AI革命,尤其是對腦力勞動的替代,與過去十年以自動化和機器人為代表的那一輪技術進步有本質不同。之前的「機器替代人」主要針對體力勞動,背後是較高的邊際成本─要真正在一個工廠、一個地區、一個行業裏使用物化的機器,需要結合生產線進行調整,這個過程需要時間,成本也相對較高。
而這一輪技術進步的特點是,新技術出現後,往往可以免費註冊,或只需極低的費用即可使用。使用成本極低,擴散速度極快。如果說以往的替代是一個區域性、行業性、漸進式的推廣過程,那麼這一次的技術使用可能是全球性的、行業快速滲透式的,影響面可能會更大。它對整個勞動力市場重組的推進速度,可能比過去的技術進步快得多。這一點值得我們高度重視。
AI發展將越來越快
在過去三年中,隨着人工智能大模型的快速發展,一些行業已經受到明顯影響。以程序員為例,編程領域在今年的衝擊尤為突出。此前,內容創作領域也受到顯著影響,比如今年Seedance的出現對視頻編輯帶來了較大影響。法務、財務及行政事務等領域同樣也受到AI的很大影響。可以看到,越來越多的職業正在進入AI的影響範圍。
最近我讀到羅比克的一篇文章,文中區分了「潛在暴露度」與「實際暴露度」或「實際替代」的概念。過去我們的研究更多聚焦於「潛在暴露」──即一個行業已經暴露在技術影響之下,但究竟會造成多大衝擊、會有多少人失業,其實是不確定的。而「實際暴露度」或「觀察到的替代」,則需要通過存量數據來觀察。用招聘信息看流量,可以了解行業對未來求職者要求的變化,這屬於「潛在暴露」;而對現有從業人員的實際影響,則屬於「實際暴露」。
羅比克文章的核心觀點正是:這兩個概念的差異非常大──流量數據展示的是潛在影響,存量數據反映的是真實衝擊。目前我們看到的更多是潛在影響,雖然能夠預見到一些趨勢,但大規模的真實衝擊尚未完全落地,存量層面還未出現劇烈波動。筆者認為這正是一個窗口期──從「潛在暴露」到「真實影響」的傳導不會太久,我們還有機會做出應對。
當前,AI技術迭代迅速,每年年初都會湧現出大量令人驚嘆的新模型和新工具。為什麼不能讓技術進步慢一點?根本原因在於國家間的博弈。最近的一次達沃斯論壇上,美國大廠也談到這個問題──雖然大家都預見到某些替代可能發生、勞動力市場可能受衝擊,但沒有人能停下來。因此我們判斷,技術進步將是快速的,且影響是全球性的,使用成本極低、擴散速度極快,這一切都難以逆轉。
不過,也有一些因素可能讓技術進步放緩。我們看到,OpenAI最近一輪融資高達1000億美元,估值達到7300億美元,投資方包括英偉達、谷歌等巨頭。這個量級相當於一個中小型國家傾全國之力投資一家企業、投入AI技術研發。那麼,未來研發還能有多大空間?我不知道,有可能研發速度會降下來。
另一個機遇來自開源模型。中國的DeepSeek等開源模型正在形成「捲」的態勢──美國投入巨資做閉源模型,而中國很快能以開源方式實現類似效果。這是否意味着高投入未必帶來獨佔收益?如果技術成果可以被廣泛共享,是否會降低研發端的投入熱情?這也是一個值得觀察的方向。如果研發投入放緩,技術進步的速度也可能慢下來,從而為勞動力市場爭取更大的反應窗口。但這一切仍有待觀察。此外,資本驅動技術快速擴張,但資本本身能否持續維持高強度的研發投入,也是一個未知數。未來是否會放緩,我們拭目以待。
提前建立預警機制
應對人工智能對勞動力市場的衝擊,關鍵在於開展前瞻性研究,構建一套動態監測與預警系統,實時跟蹤勞動力市場的變化,精準把握技術進步對特定職業、任務及技能的影響,並及時向從業者和政府部門發出提醒和預警。這樣,勞動者可以提前準備轉崗或技能提升,政府也能有針對性地組織培訓,從而避免大規模失業,推動勞動力結構的平穩調整。因此,建立動態監測系統至關重要。
動態監測系統的基本邏輯是什麼?傳統的勞動力市場研究往往以職業、行業或地區為單位,但在AI快速滲透的背景下,我們更需要將勞動力市場「原子化」──即拆解到任務和技能這兩個底層維度。以客服崗位為例,三年前和現在的職業名稱沒變,但具體從事的任務構成已經完全不同。因此,我們要透過表面的職業名稱,觀察職業內部的任務重組和技能需求的變化。
我們利用智聯招聘等數據,將招聘信息解構為任務和技能兩個維度。目前,國際通用的任務分類約有2萬種,技能分類約3萬種,但這一標準類似「元素周期表」,是相對靜態的,近些年變化不大。而我們真正需要的是動態追蹤──通過分析崗位描述(JD)的變化,發現哪些新任務、新技能出現,哪些舊任務、舊技能消失,不斷更新這個「元素周期表」。
此外,還需要關注這些「元素」的組合方式。勞動力市場的重組,本質上就是任務和技能的組合方式在發生變化。我們採用網絡分析方法,觀察哪些任務和技能開始頻繁組合,當組合趨於穩定並形成新的模式時,可能就意味着一個新職業的誕生。我們不能等到職業名稱消失時才意識到變化,而要在其內部結構悄然演變時就捕捉到趨勢。
當前國際上通行的「暴露度」算法,已經有些過時。傳統方法往往通過詢問AI能否完成某項任務的50%工作量來判斷,輸出的是0或1的二元變量。但現實遠比這複雜:50%替代和90%替代,對就業的影響天差地別。以程序員為例,過去幾年可能只是50%替代,現在已接近完全替代,但單一數據點無法反映這種變化。因此,我們需要將暴露度從一個二元指標拓展為連續變量,更精細地衡量替代程度。
更重要的是,現有的暴露度算法只能說明某個職業「暴露」在風險之下,並不能直接等同於「被替代」。我們觀察中國、新加坡、美國的數據發現,大量職業的暴露度集中在0.7到0.8之間,但這些職業中有的需求下降,有的需求不變,有的甚至需求上升。這說明,同樣的暴露度並不必然導致替代。因此,我們希望對暴露度指標進行優化,賦予它「溫度」和「態度」──既能反映暴露程度,也能預測替代的可能性。這是我們當前方法論探索的重點。
最後,筆者認為當前階段應當加快建立就業預警機制,並完善社會保障體系。今年兩會提出了構建「就業友好型社會」的方向,其中包含一系列政策安排。在全流程監控AI應用風險的基礎上,相信後續會出台更多配套政策,幫助社會逐步適應快速的技術迭代。
(作者為北京大學國家發展研究院副院長)


評論